Until recently, every program Rainbow-OS ran shared one address space with the
kernel, at full privilege. A program compiled with the built-in C compiler wasn’t
isolated from anything — it could scribble over kernel memory, run privileged
instructions, and crash the whole machine. This update fixes that: programs now
run in Ring 3 (userland), reach the kernel only through a single
syscall gate, and a buggy or malicious program gets killed instead of taking the
system down with it.
Why there was no boundary
The original design was the simplest thing that works: the bootloader set up a
flat GDT with only Ring 0 segments, paging mapped every page as supervisor, and
running a program was a plain function call. „Kernel services“ were a table of
function pointers the program called directly. Fast and easy — and with zero
protection. The proof was a four-line program: write a byte to a kernel address,
and it just… worked.
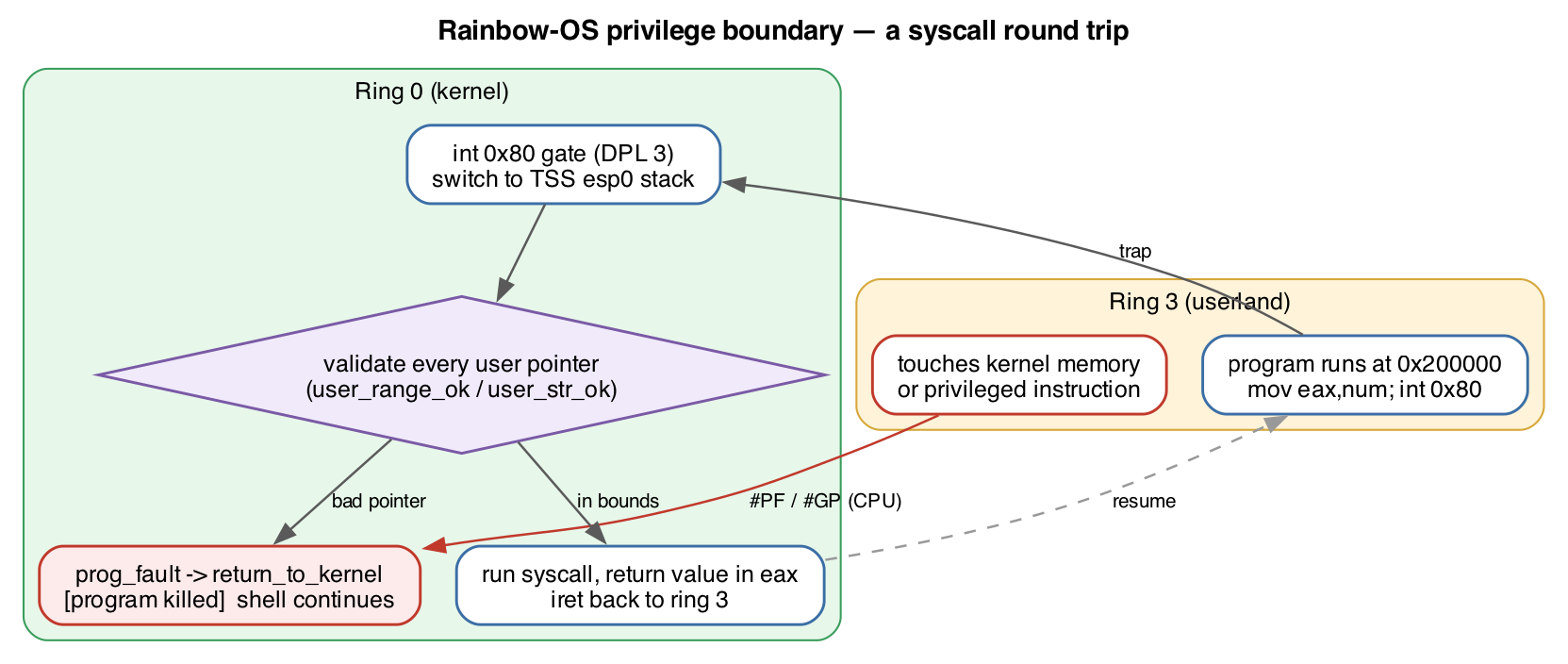
The four pieces of a privilege boundary
Adding real separation on a 386/486-class CPU means cooperating with the
hardware’s protection rings. It came down to four parts:
- GDT + TSS. A new descriptor table adds Ring 3 code/data
segments (DPL 3) alongside the kernel ones, plus a Task State Segment. The TSS
holds the kernel stack pointer the CPU switches to whenever it re-enters Ring 0
— without it, the first interrupt from userland triple-faults. - A syscall gate. An
int 0x80entry in the
interrupt table, marked DPL 3 so userland is actually allowed to invoke it. The
program puts a syscall number in a register and traps; the kernel handles it and
returns. The compiler was changed to emitint 0x80instead of the old
direct call. - User pages. Only the program’s own memory window is marked
user-accessible in the page tables. The kernel, the framebuffer, and the page
tables themselves stay supervisor-only — so a Ring 3 program physically
cannot read or write them. - Entering and leaving Ring 3. The kernel drops to userland with
aniret, and comes back via a small coroutine-style swap when the
program exits or faults.
Proving it actually isolates
Correct output from a normal program doesn’t prove anything — it would
look identical whether the program ran privileged or not. The real test is making
a program misbehave. So: the same four-line „write to kernel memory“ program now
produces a page fault the instant it tries the store. The fault’s error code has
the user bit set, which is the hardware confirming the access came from
Ring 3. The kernel catches it, prints [program killed: page fault],
and drops back to the shell — which keeps running. That recovery, not the
fault itself, is the satisfying part.
Closing the back door: the confused deputy
There was a subtler hole. Ring 3 can’t touch kernel memory directly anymore
— but a syscall runs in the kernel, on the program’s behalf. If the
kernel blindly trusts a pointer the program hands it, the program can ask the
kernel to do the dirty work for it: „please write this byte to that kernel
address.“ That’s the classic confused-deputy attack, and it would
have made the whole Ring 3 effort pointless.
The fix is to treat every pointer crossing the syscall boundary as hostile. The
argument block, string arguments, buffer ranges, even each variadic
printf argument — all are bounds-checked against the program’s
own memory window before the kernel dereferences anything:
static int user_range_ok(uint32_t addr, uint32_t len) {
uint32_t end = addr + len;
return len == 0 ||
(end >= addr && /* no wraparound */
addr >= USER_REGION_BASE && end <= USER_REGION_TOP);
}
Anything pointing outside the window kills the program with
[program killed: bad syscall pointer]. A test program that asks the
kernel to poke a kernel address is now stopped cold, where a week ago it would have
succeeded.
What this is, and isn’t
Rainbow-OS now has a genuine userland/kernel boundary: unprivileged programs, a
controlled syscall interface, hardware-enforced memory protection, and fault
recovery instead of a system halt. It is not yet multitasking, and there’s still a
single shared address space (one program at a time), so true per-process isolation
— separate page tables per program — is the next milestone. But the
hard part, the privilege boundary itself, is in place. A program can now crash, and
the operating system simply shrugs and gives you back your prompt.